COLUMN
コラム
2026年03月16日
「次の単語を予測するだけ」でChatGPTが動いている。Transformerの心臓部Attentionを26分で理解する
1. ChatGPTの本質 — 「次の単語を予測する」だけで文章が生成される仕組み
ChatGPTは、まるで人間と会話しているかのように自然な文章を生成します。しかし、その内部では驚くほどシンプルな仕組みが動いています。
それは「次に来る単語の確率分布を予測し、そこからランダムにサンプリングする」という処理の繰り返しです。
例えば、「昔々あるところに」という入力があったとき、モデルは「おじいさん」「若者」「王様」などの候補それぞれに確率を割り当てます。
この確率分布から1つの単語をサンプリングし、元の文章に追加。
すると「昔々あるところにおじいさんが」となり、これを再度モデルに入力して「次の単語」を予測させます。
このサイクルを繰り返すだけで、長い文章が生成されるのです。
モデルサイズで変わる文章品質
興味深いのは、モデルのサイズが変わると生成される文章の質が劇的に変化することです。
GPT-2(約15億パラメータ)では意味の通らない文章になりがちですが、GPT-3(1,750億パラメータ)では急に意味をなす長文ストーリーが生成されるようになります。
この「パラメータ数の増加が品質を向上させる」という現象が、LLM(大規模言語モデル)開発競争の背景にあります。
2. Transformerのデータ処理フロー — トークン化から確率分布出力まで
ChatGPTの心臓部であるTransformerは、2017年にGoogleの研究者が発表した「Attention is All You Need」という論文で初めて登場しました。
現在のAIブームの中心的技術として、GPT、BERT、Gemini、Claudeなど、ほぼすべての主要LLMに採用されています。
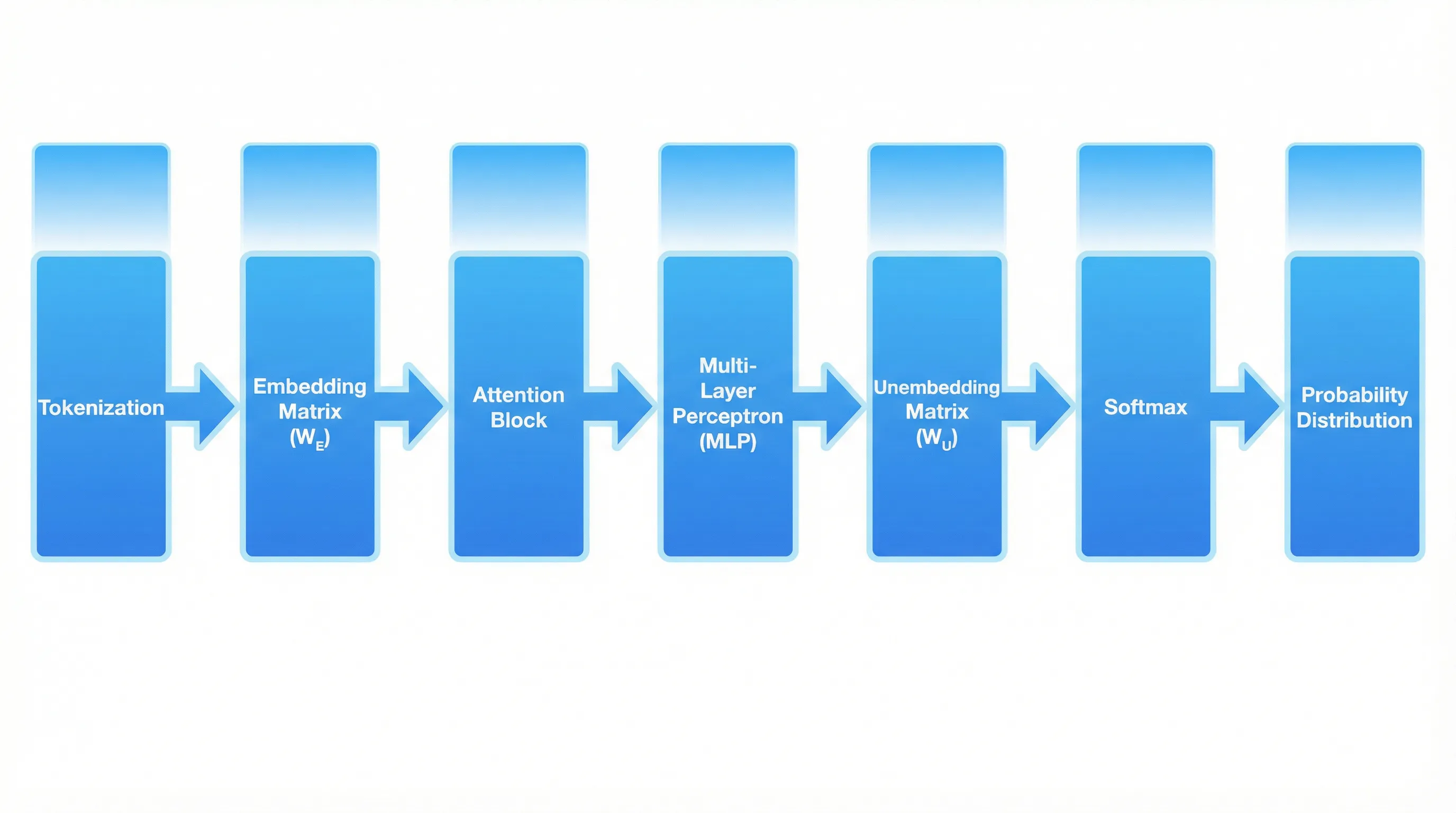
Transformerがテキストをどう処理するか、ステップごとに見ていきましょう。
5つの処理ステップ
- ① トークン化:入力テキストを小さな単位(トークン)に分割します。トークンは単語そのものだけでなく、単語の一部(例: "transform" → "trans" + "form")や記号も含まれます。GPT-3の語彙サイズは52,257トークンです
- ② 埋め込み(ベクトル化):各トークンをベクトル(数のリスト)に変換します。これは埋め込み行列(W_E)と呼ばれる重みを使って行われ、GPT-3では各トークンが12,288次元のベクトルになります
- ③ アテンションブロック:各ベクトルが、他のベクトルとの関係性を基に情報を更新します。「どの単語が他のどの単語と関連しているか」を把握し、文脈に応じた意味を獲得します
- ④ 多層パーセプトロン(MLP):各ベクトルに対して、複数の「質問」をして答えに基づいて値を更新します。これは並列処理され、ベクトル同士は干渉しません
- ⑤ 確率分布の出力:最後のベクトルを掘り出し行列(W_U)で変換し、ソフトマックス関数で正規化して、次に来るトークンの確率分布を生成します
このステップ③と④(アテンションブロック → MLP)が何度も繰り返され、最終的に全ての文脈情報が最後のベクトルに集約されます。
GPT-3では、この繰り返しが96層あります。
3. 単語埋め込み — 「12,288次元の空間」で言葉の意味を操作する
「単語をベクトルにする」という発想は、Transformerの前からある技術ですが、非常に強力です。
GPT-3では、各単語が12,288次元のベクトルとして表現されます。
これは3次元空間の「座標」を、12,288個の軸に拡張したイメージです。
似た意味の単語は「近くに配置」される
訓練されたモデルでは、意味の似た単語が高次元空間で近くに配置されます。
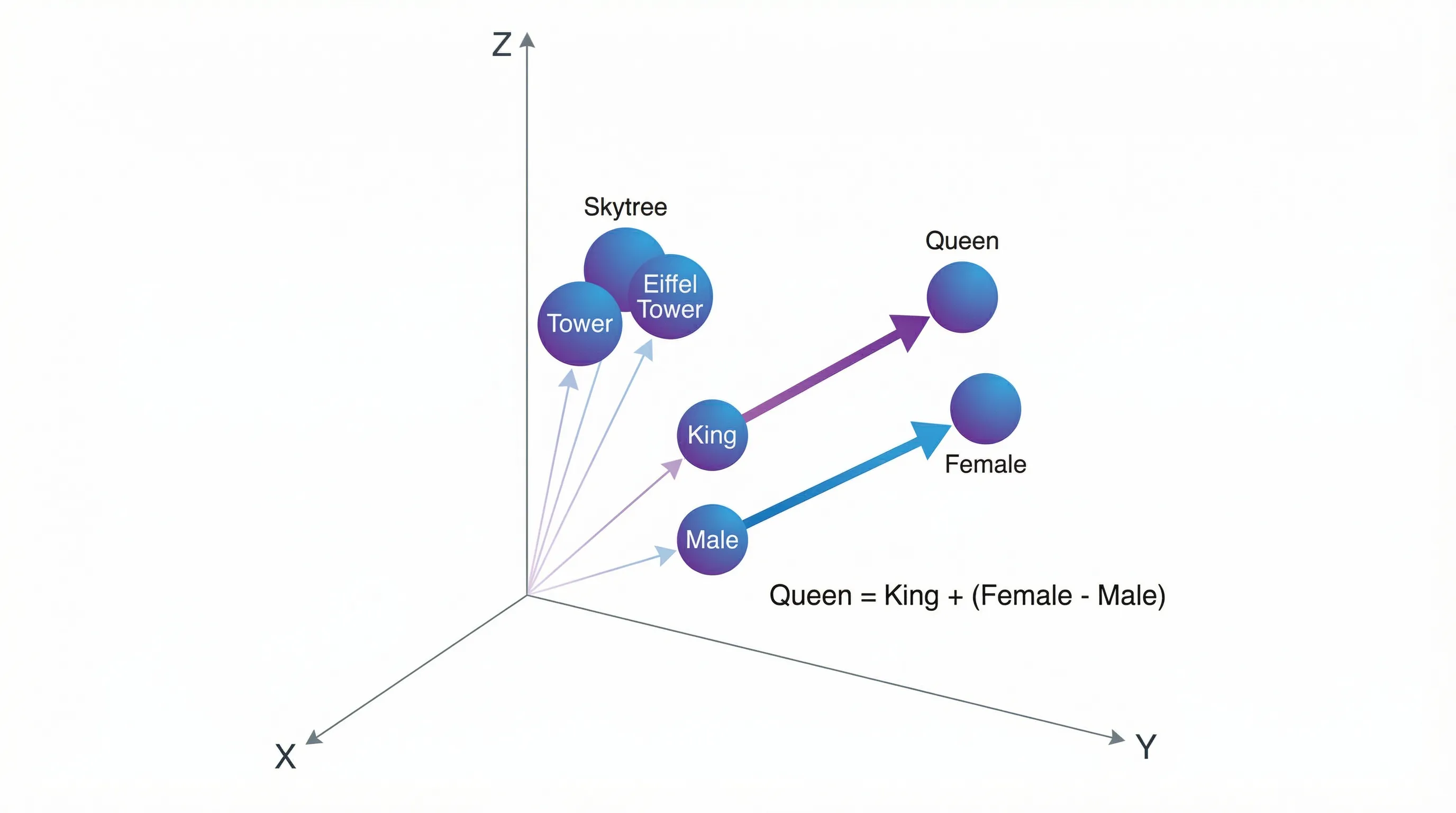
例えば「タワー」のベクトルに最も近い単語を探すと、「スカイツリー」「エッフェル塔」「展望台」などが見つかります。
これは、モデルが「タワーっぽさ」という抽象的な概念を、空間の方向として学習しているためです。
ベクトル演算で意味を操作できる
さらに驚くべきことに、ベクトルを足し引きすることで意味を操作できます。
- 女王 = 王 + (女性 - 男性):「女性」と「男性」のベクトルの差を取ると「性別の方向」が得られ、これを「王」に足すと「女王」に近いベクトルになります
- ムッソリーニ = ヒトラー + (イタリア - ドイツ):同様に「国の方向」を操作することで、歴史上の人物を対応づけられます
- 「複数形っぽさ」の数値化:「cats - cat」というベクトルと他の単語の内積を取ると、その単語が「どれだけ複数形っぽいか」を数値化できます
この仕組みが、AIが「言葉の意味」を理解しているように見える理由です。
実際には意味を「暗記」しているのではなく、高次元空間での位置関係として学習しているのです。
4. Attention機構 — 文脈で単語の意味を更新する「心臓部」
単語埋め込みには1つ問題があります。
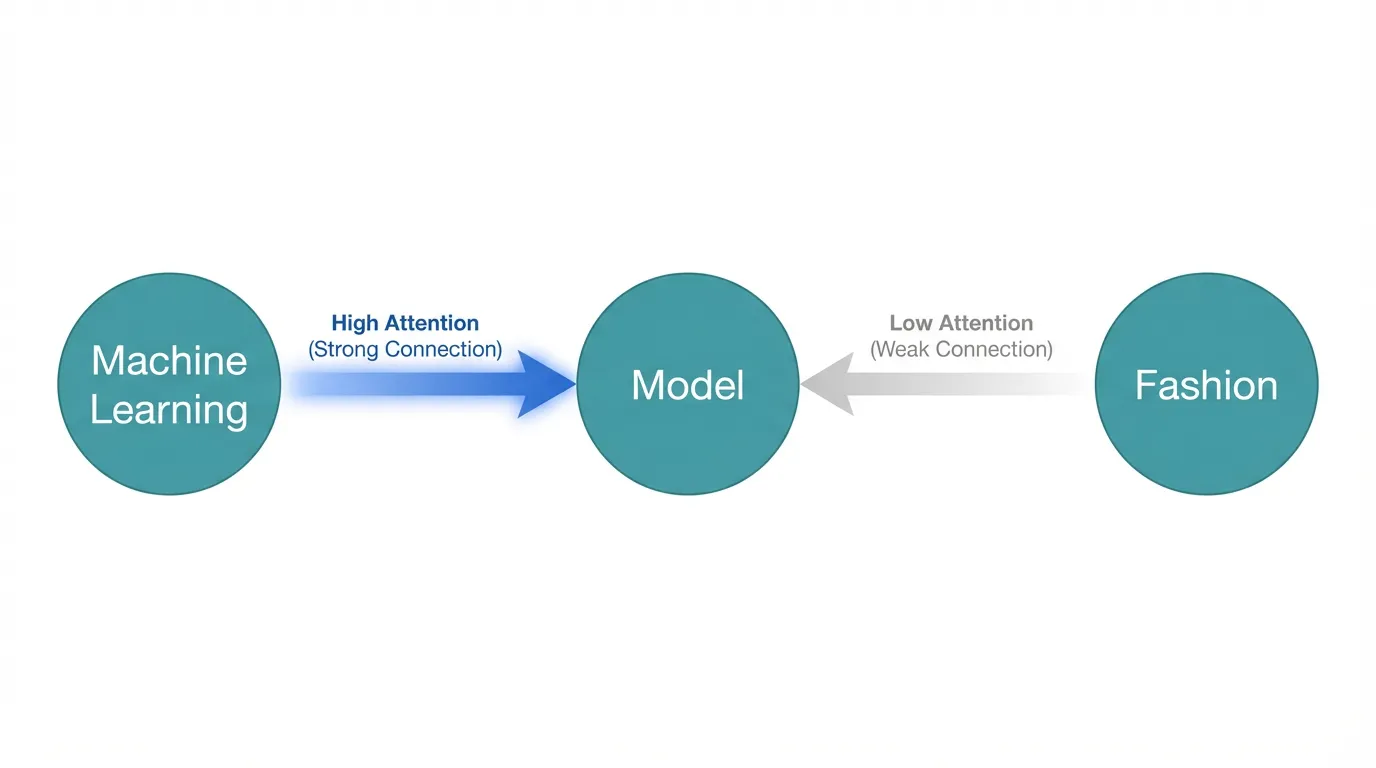
「モデル」という単語は、「機械学習モデル」と「ファッションモデル」で意味が全く異なるのに、最初の埋め込み段階では同じベクトルが割り当てられてしまうことです。
この問題を解決するのがAttention機構です。
Attentionは「ある文脈でどの単語が他のどの単語と関連しているのか」を把握し、それに基づいてベクトルの値を更新します。
Attentionが文脈を捉える仕組み
例えば「機械学習のモデルを選定する」という文があったとき、Attention機構は以下のように動作します。
- 「モデル」というトークンのベクトルが、他の全てのトークンとの「関連度」を計算します(内積を使用)
- 「機械学習」との関連度が高いと判定され、「ファッション」がないため「ファッションモデル」の意味は弱まります
- 関連度に基づいて、「モデル」のベクトルが「機械学習寄り」に更新されます
この処理により、同じ「モデル」という単語でも、文脈によって異なる意味を獲得できるのです。
Attention機構は、Transformerの名前の由来でもある「Attention is All You Need(Attentionこそ全て)」論文のタイトルが示す通り、この技術の心臓部と言えます。
5. ソフトマックス関数と温度パラメータ — 確率分布の「鋭さ」を調整する
最後のステップでは、ベクトルを「次のトークンの確率分布」に変換する必要があります。
ここで使われるのがソフトマックス関数です。
ソフトマックスの役割
行列計算の結果は、負の値や1より大きい値を含む「ただの数のリスト」です。
これを確率分布(各値が0〜1、合計が1)に変換するのがソフトマックスです。
具体的には、各数値でeの累乗を取り(正の値にする)、その合計で割ります(合計を1にする)。
温度パラメータで「創造性」を調整
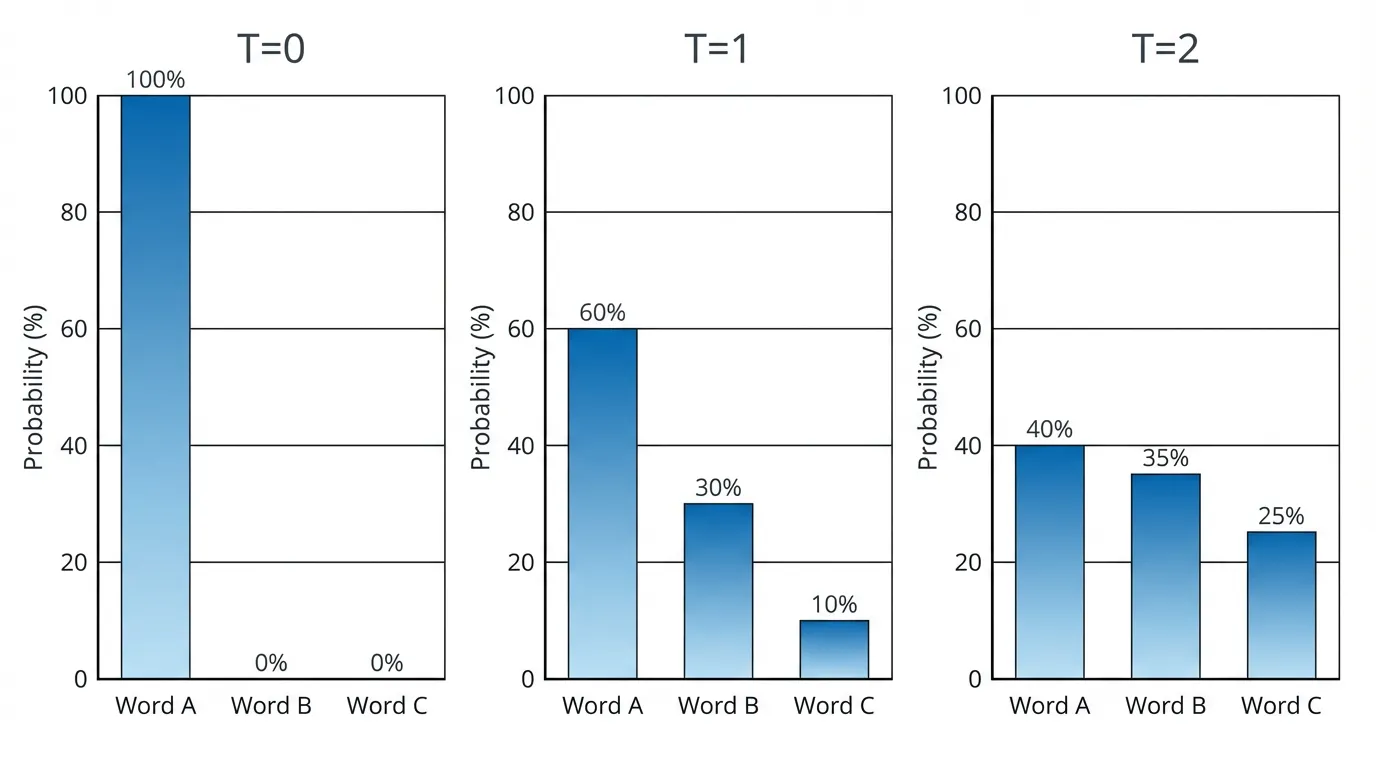
ChatGPTなどのツールでは、温度パラメータ(T)で分布の「鋭さ」を調整できます。
- 温度0:常に最も確からしい単語だけを選ぶ。生成される文章は定型的で予測可能(例: 「昔々あるところに3匹のくまが…」のような決まり文句)
- 温度1:標準的なバランス。確率に応じて単語が選ばれる
- 温度2:低確率の単語も選ばれやすくなり、創造的だが出鱈目になるリスクも上がる。GPT-3のAPIでは温度2以上が禁止されています(品質保証のため)
この温度パラメータの調整が、ChatGPTの「創造性」をコントロールする仕組みです。
6. GPT-3の1,750億パラメータの内訳 — 「28,000個の行列」に整理する
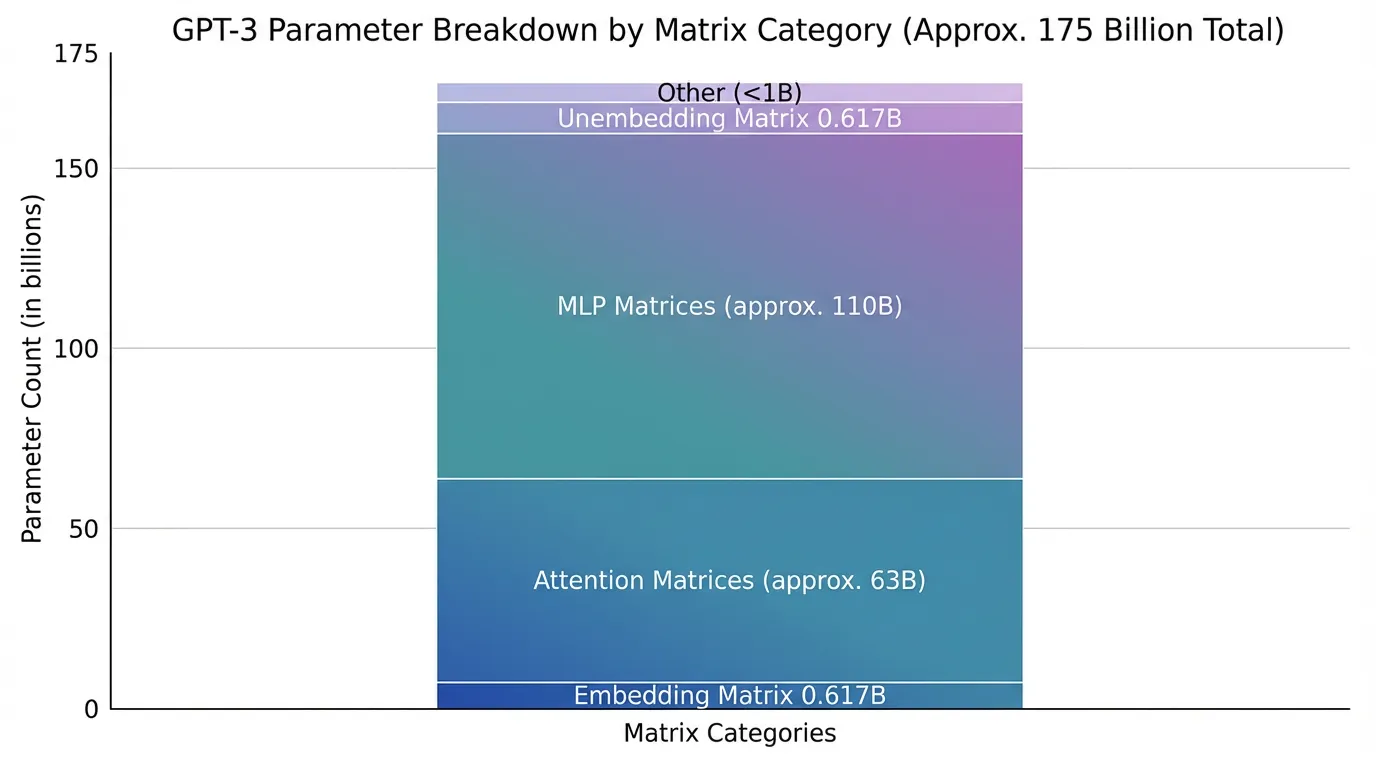
GPT-3の「1,750億パラメータ」という数字は有名ですが、その内訳を理解している人は少ないでしょう。
実は、この膨大な数は28,000個未満の行列に整理でき、8つのカテゴリに分類されます。
パラメータ数の計算例
- 埋め込み行列(W_E):語彙サイズ 52,257 × 埋め込み次元 12,288 = 約6.17億パラメータ
- 掘り出し行列(W_U):埋め込み次元 12,288 × 語彙サイズ 52,257 = 約6.17億パラメータ
- アテンション・MLP行列:残りの約1,738億パラメータは、96層のアテンションブロックと多層パーセプトロンに分散
埋め込みと掘り出しだけで約12億パラメータ(全体の約7%)を占めます。
残りの93%が、文脈理解と意味更新のための層に割り当てられているのです。
2026年のトレンド: モデルの小型化
2026年現在、LLM業界では「小型で高性能」なモデルが注目されています。
Meta社のLLaMA 2、MicrosoftのPhi-2など、パラメータ数を抑えつつ性能を維持したモデルが登場しています。
「1,750億パラメータは本当に必要か?」という問いに対し、技術リードは自社のユースケースとコストのトレードオフを判断する必要があります。
このパラメータ数の構造理解が、モデル選定の判断材料になるのです。
7. 実務でどう活かすか — Transformerの仕組み理解が実務に与える3つの価値
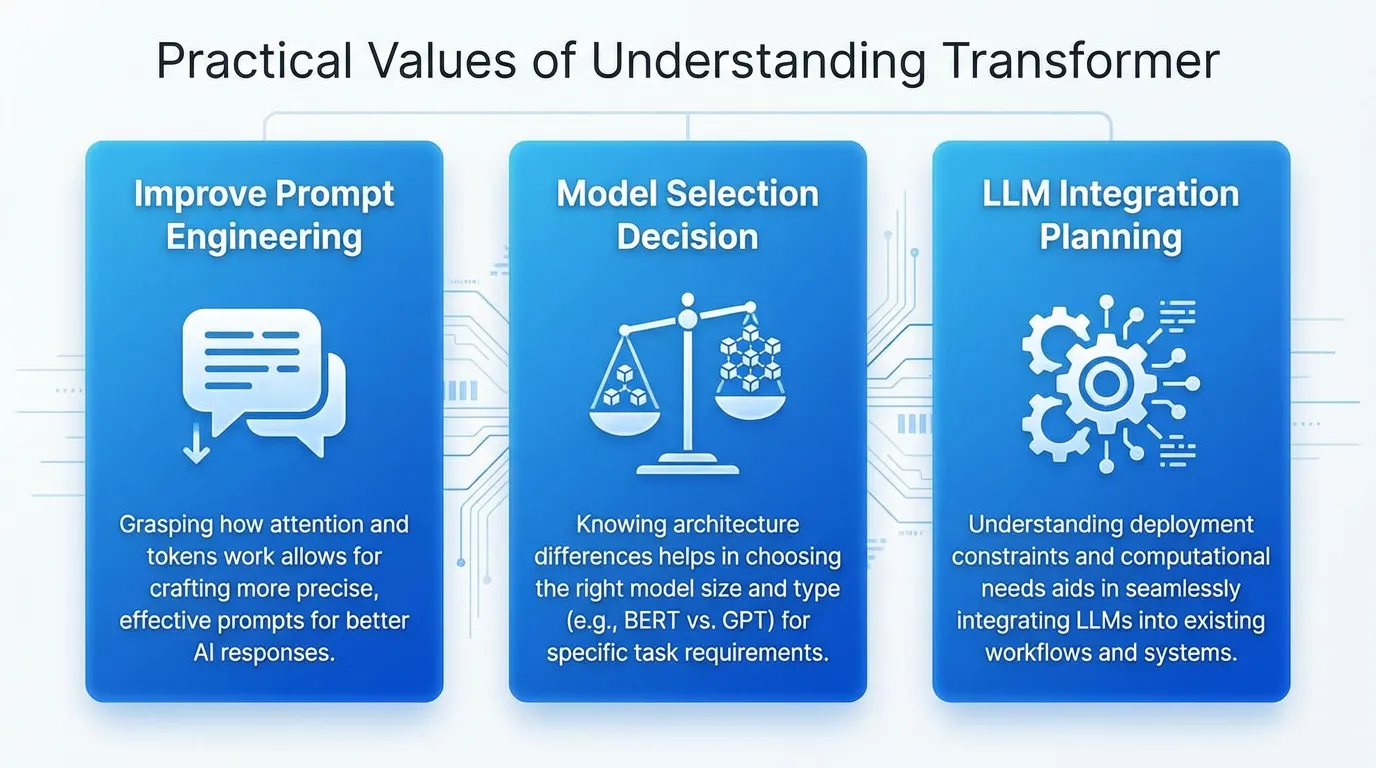
Transformerの仕組みを理解すると、実務で以下の3つの価値が得られます。
① プロンプトエンジニアリングの精度向上
埋め込み空間の仕組みを知ると、「似た意味の単語を意識的に使う」「曖昧な表現を避ける」といったテクニックの根拠が理解できます。
例えば、「データ分析」と「データサイエンス」は埋め込み空間で近い位置にありますが、プロンプトでどちらを使うかで結果が微妙に変わります。
この知識があれば、試行錯誤が減り、初回から高精度なプロンプトを書けるようになります。
② モデル選定の判断材料
GPT-4、Gemini、Claudeなど複数のLLMがある中で、「どれを選ぶべきか」を技術的に説明できるようになります。
例えば、Gemini 1.5は数十万トークンの長文対応(コンテキストサイズが大きい)、Claude 3 Opusは長期記憶対応といった違いが、Transformerの構造を理解していれば納得できます。
単に「高性能だから」ではなく、「自社のユースケースにこのアーキテクチャが適している」と根拠を持って判断できるのです。
③ 自社サービスへのLLM組み込み判断
「自社サービスにLLMを組み込むべきか?」という判断をする際、パラメータ数とコストのトレードオフを理解している必要があります。
例えば、RAG(Retrieval-Augmented Generation)を導入する場合、埋め込みベクトルの仕組みを知っていれば、ベクトルデータベースの設計が理解しやすくなります。
また、オンプレミスでLLMを運用する場合、「どのサイズのモデルなら自社インフラで回せるか」を見積もる際、パラメータ数の内訳が判断材料になります。
こうした実務判断において、Transformerの仕組み理解は「ただの技術的好奇心」ではなく、「ビジネス価値を生む知識」に変わるのです。
LLMを業務に組み込む次のステップとして、Captain.AIのようなAIエージェント実行基盤を活用することで、プロンプトエンジニアリングで培ったスキルを業務自動化に展開できます。
TransformerベースのLLMを「同僚」として業務に組み込み、チーム全員がAIと協働する環境を実現する—それが次世代のAI活用の形です。
8. まとめ — Transformerを理解したら、次は「AIと協働する」ステップへ
この記事では、ChatGPTの心臓部であるTransformerの仕組みを、視覚的に解説しました。
- 「次の単語を予測する」だけで文章が生成される:ChatGPTは確率分布のサンプリングを繰り返すだけで、長い文章を作り出します
- 12,288次元の埋め込み空間で意味を操作:単語はベクトルとして表現され、高次元空間での位置関係が「意味」になります。ベクトル演算で「女王 = 王 + (女性 - 男性)」のような操作が可能です
- Attention機構が文脈を理解:「モデル」という単語が「機械学習モデル」なのか「ファッションモデル」なのか、文脈から判断して意味を更新します
- 1,750億パラメータは28,000個の行列に整理できる:膨大に見える数字も、構造を理解すれば整理可能。モデル選定やコスト見積もりの判断材料になります
AIを"使う"フェーズは終わりつつあります。
これからは、AIと"協働"し、チーム全体の生産性を底上げする組織が競争優位を握る時代です。
Transformerの仕組みを理解したあなたなら、もう「ChatGPTに質問を投げる」だけでは物足りないはず。
次は、LLMを「業務の同僚」として組み込むステップへ。
Captain.AIなら、自社業務に特化したAIエージェントをノーコードで構築し、チーム全員がAIと協働する環境を実現できます。
プロンプトエンジニアリングで培った「AIとの対話スキル」を、業務自動化に活かす時が来ました。
興味がある方は、まず無料相談からご検討ください。